From Recurrent Networks to Transformers, How Attention Changed Everything
This is part 1 of 2
What is natural language and how do we make machines speak our language?
Natural language is how humans communicate be it through words, sentences, or context. Teaching machines to understand and generate human language is one of the most challenging problems in AI, since machines only understand numbers or 0 and 1’s.
The Problem with Traditional Approaches
Before Transformers (the model that powers GPT) we used:
- RNNs (Recurrent Neural Networks): Process text word by word, but struggle with long sequences
- LSTMs (Long-Short Term Memory): Better at handling long-term dependencies, but still sequential
- GRUs (Gated Recurrent Unit): Faster than LSTMs but similar limitations
Let’s go over them one by one
Recurrent Neural Networks
Traditional Neural Networks
When you think about traditional neural networks, which I covered in depth here
Basically, we go from input X which we then multiply with the weight matrix and apply the activation function and keep continuing this process to get the output Y.
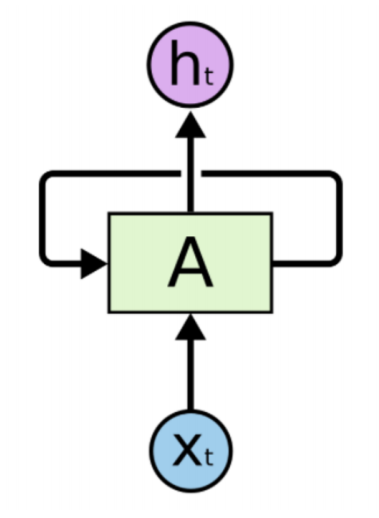
source : https://goodboychan.github.io/images/simpleRNN.png
How RNNs carry over context
The novel thing about the RNNs and how they in their time revolutionized natural language. They introduced a feedback loop into each cell - which would basically add the information from all the previous layers.
Consider the following architecture of a simple RNN architecture for a stock price predictor with 3 days worth of data:
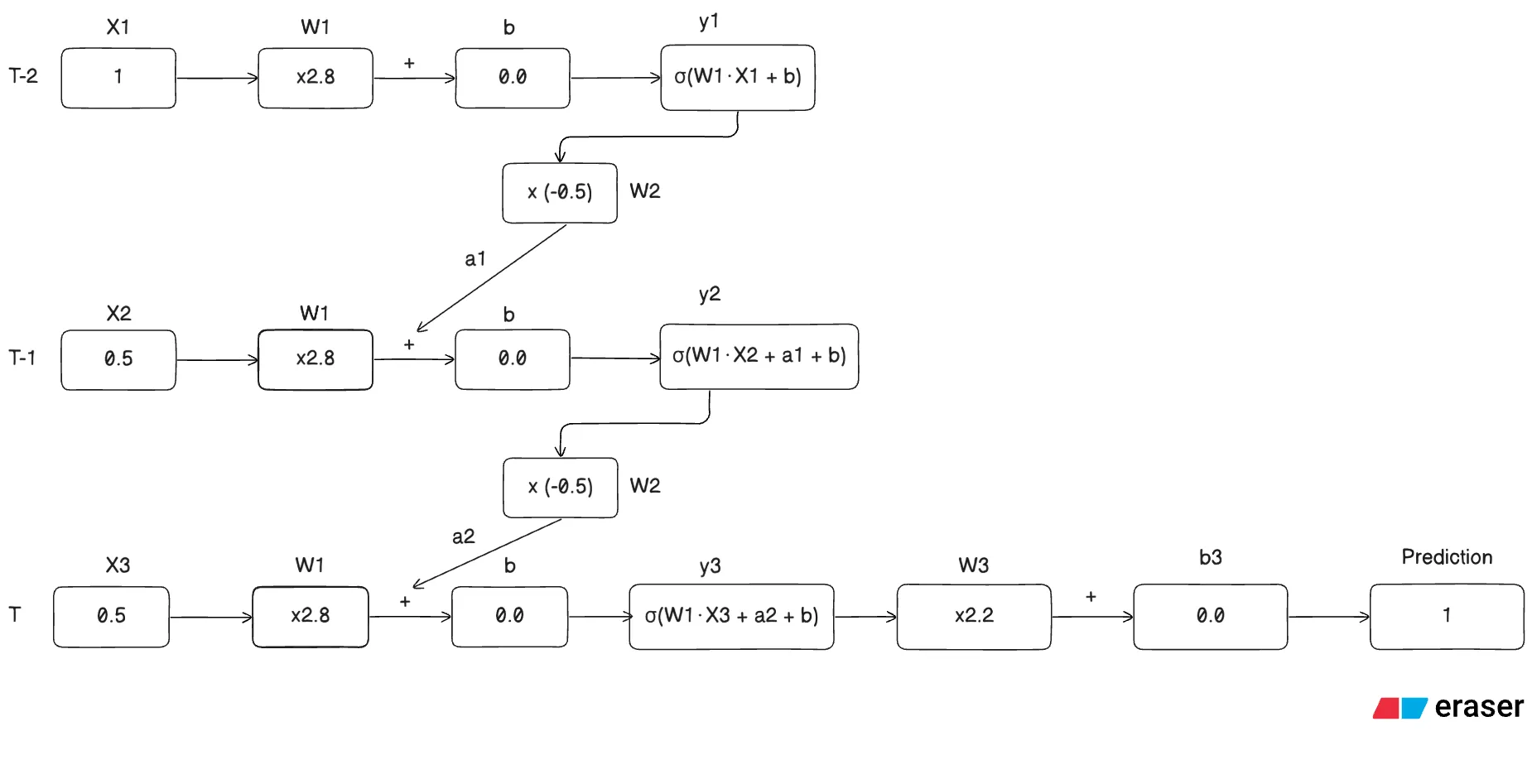
Note: The weights and biases for all the three timesteps are the same, this is the novelty of this network which helps carry over context to the next timestep
What’s happening in the given architecture
Step 1: for timestamp T-2 we calculate the activation for input ,
for the feedback loop we calculate the following,
Step 2: for timestamp T-1 we calculate the activation for input and add the activation ,
for the feedback loop we calculate the following,
Step 3: for timestamp T we calculate the activation for input and add the activation ,
Step 4: Calculate the prediction with a simple feed forward operation,
Note: The activation for the final layer depends on the kind of task you are trying to perform,
- Linear: Regression
- Sigmoid: Binary classification
- Softmax: Multi-class classification
Note: We usually use tanh function for the hidden state in a RNN network
Why we usually don’t use RNN’s anymore
Exploding OR Vanishing Gradients
- Exploding Gradients
Imagine W2 to be a constant number for now,
Now imagine we have 100 timesteps (which still isn’t a lot of data to train a decent RNN) the final layer becomes,
Now, these huge values creep into the gradients we calculate during gradient descent and will eventually “explode” them and will make it harder for the gradient descent algorithm to converge since we take bigger steps in the update rule.
- Vanishing Gradients
Similarly, Imagine W2 to be a constant number for now,
Now imagine we have 100 timesteps (which still isn’t a lot of data to train a decent RNN) the final layer becomes,
Similarly, these extremely small creep into the gradients we calculate during gradient descent and will eventually make them “vanish” and make it harder for the gradient descent algorithm to converge since we take almost don’t change our W values
To solve these we came up with the LSTM network or the Long-Short Term Memory Network.
Long-Short Term Memory Networks
Now, let’s look at a model that tried to solve the vanishing / exploding gradient problem.
The main idea behind the LSTM is to add 2 different pathways for long-term and short-term memories.
How it tackles exploding / vanishing gradients problem? The long-term memory pathway lacks weights and biases which avoids the said problem.
Before we dive into the LSTM architecture let’s see what the hadamard product is
It’s basically element wise multiplication.
The Architecture
Stage 1 : Forget Gate
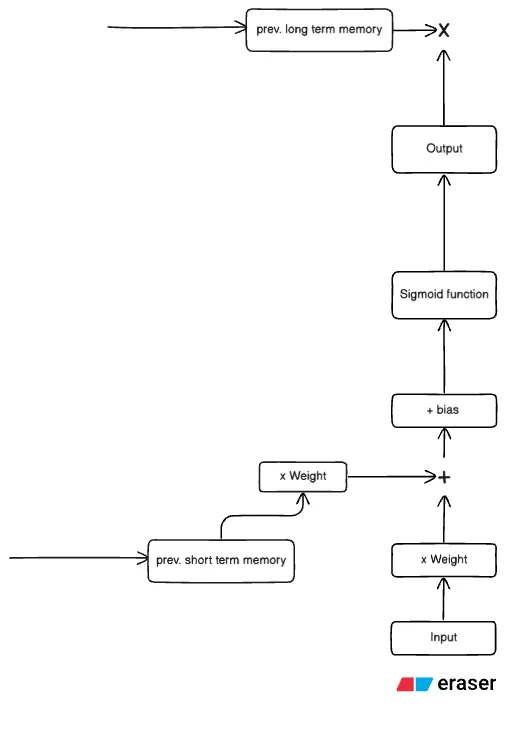
Part 1 - The Math
Note: We assume this to be the first LSTM cell, and hence there is no contribution from the previous cell. This will be clearer once you understand all the gates in a LSTM network.
Part 2.1 - What’s happening?
The first stage determines what percentage of the long-term memory should be “forgotten”, hence the name. This is because the output of the sigmoid function lies between 0 and 1. When this value is multiplied by the previous timestep’s long-term memory, it decides how much information is retained and how much is discarded.
Part 2.2 - Cases
Case 1: Input which results in activation close to 0
This would result in the result to become 0, that implies we completely forget the long-term memory to this point in the network
Case 2: Input which results in activation closer to 1
The more the activation is closer to 1, the less the long-term memory is updated.
Stage 2 : Input Gate
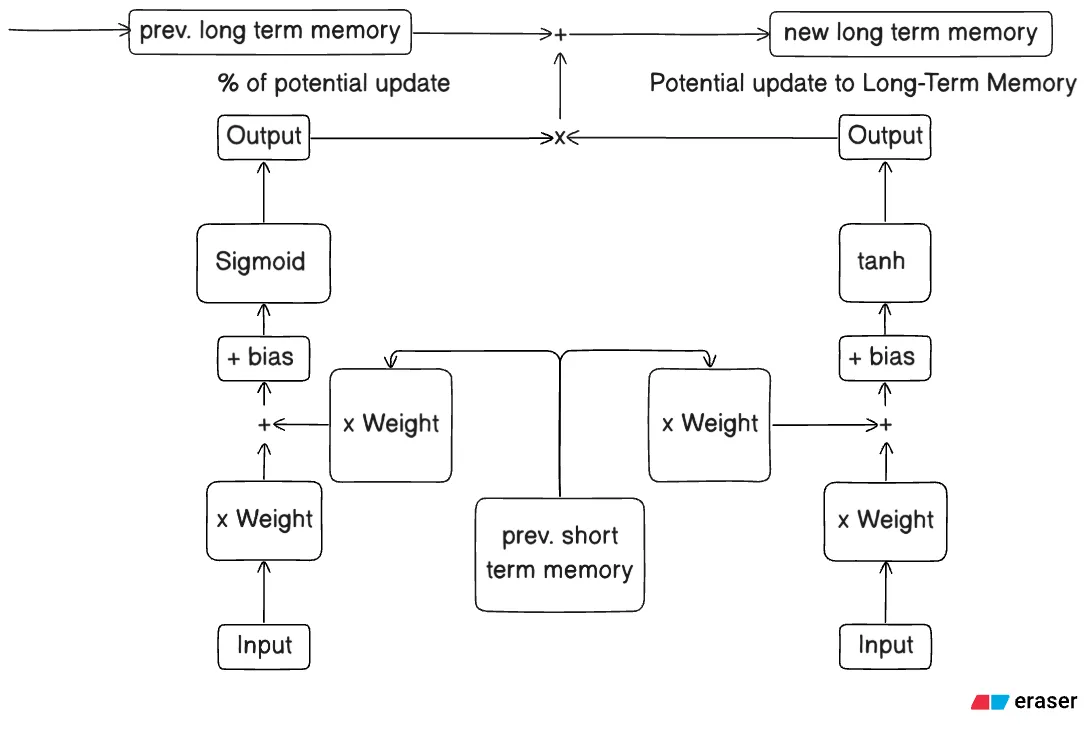
Part 1.1 - The Math - candidate cell (right)
Part 1.2 - The Math - sigmoid cell (left)
Part 1.3 - The Math - Final computation
Part 2 - What’s happening?
Each input gate has 2 cells - candidate or tanh cell and sigmoid cell. The candidate cell calculates the potential update to the Long-Term Memory and the sigmoid cell calculates the percentage of the potential update that actually goes through.
Part 2.1.1 - Candidate Cell (Right)
This cell is responsible for calculating the potential effect this set of input, short-term memory, weight and bias will have on the Long-Term Memory.
Part 2.1.2 - Sigmoid Cell (Left)
This cell is responsible for calculating the percentage of the potential memory to save or update the Long-Term Memory given a set of input, short-term memory, weight and bias.
Part 2.2 - Cases
Case 1.1: tanh activation produces a negative value
This would negatively influence the Long-Term Memory given the sigmoid cell ≠ 0
Case 1.2: tanh activation produces a positive value
This would positively influence the Long-Term Memory given the sigmoid cell ≠ 0
Case 1.3: sigmoid activation produces a value of 0
This would not influence the Long-Term Memory at all since the sigmoid cell = 0
Stage 3 : Output Gate
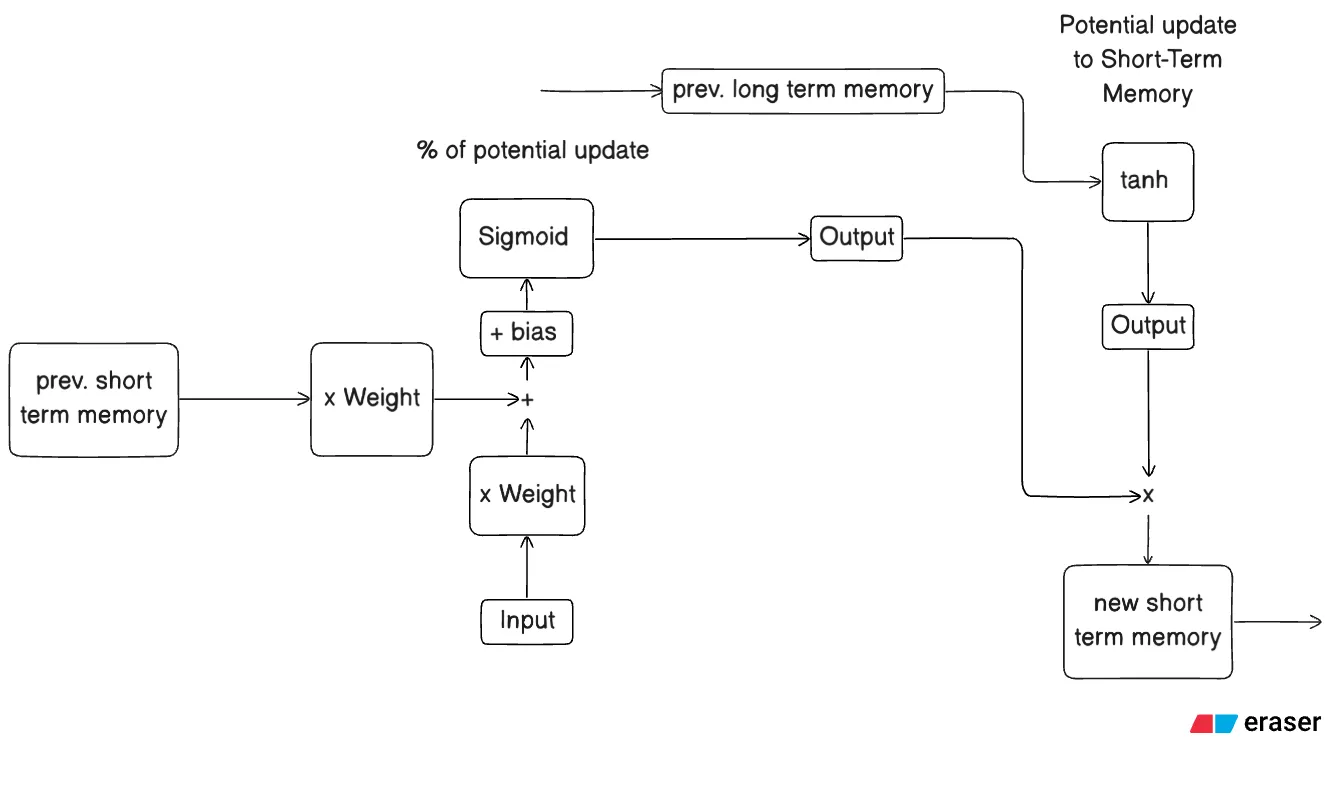
Part 1.1 - The Math - sigmoid cell (left)
Part 1.2 - The Math - candidate cell (right)
Part 1.3 - The Math - Final computation
Part 2 - What’s happening?
Each input gate has 2 cells - candidate or tanh cell and sigmoid cell. The candidate cell calculates the potential update to the Short-Term Memory and the sigmoid cell calculates the percentage of the potential update that actually goes through.
Part 2.1.1 - Candidate Cell (Right)
This cell is responsible for calculating the potential effect the long-term memory will have on the Short-Term Memory and hence the output.
Part 2.1.2 - Sigmoid Cell (Left)
This cell is responsible for calculating the percentage of the potential memory to save or update the Short-Term Memory given set of input, prev. short-term memory, weights and bias.
Part 2.2 - Cases
Case 1.1: tanh activation produces a negative value
This would make the Short-Term Memory negative given the sigmoid cell ≠ 0
Case 1.2: tanh activation produces a positive value
This would make the Short-Term Memory positive given the sigmoid cell ≠ 0
Case 1.3: sigmoid activation produces a value of 0
This would return the output of the LSTM unit = 0, since we multiply both activations.
Gated Recurrent Unit Network
GRU in essence is a modified and optimized version of an LSTM network, it uses fewer gates to achieve similar results. The GRU has 2 gates - reset gate and update gate, both the gates have analogous architecture like the input-output gates in an LSTM, just the trainable parameters (weights and biases) vary.
The Architecture
Reset and Update Gate - Analogous Architecture
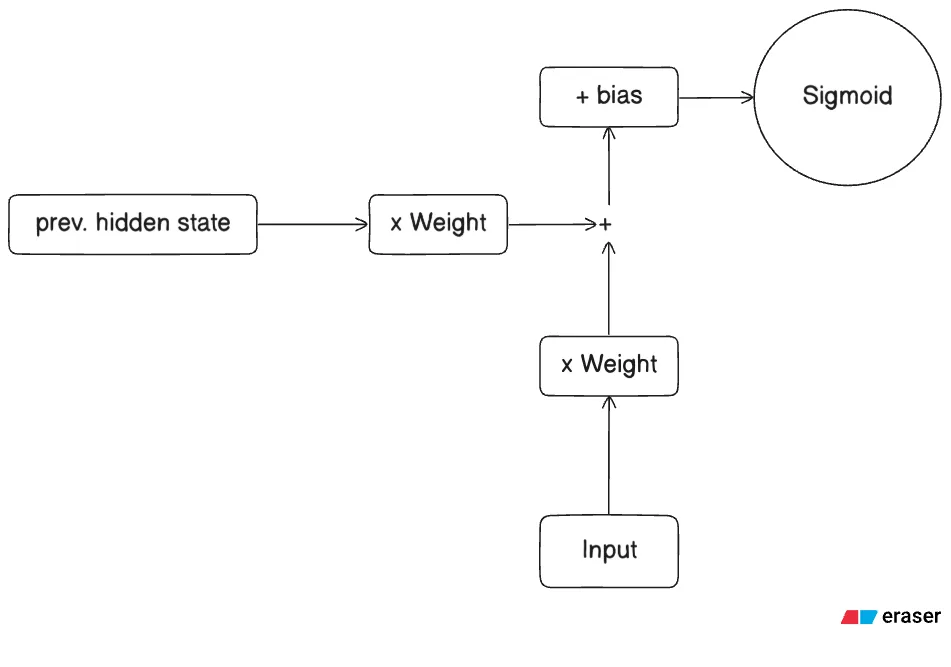
Reset Gate
Part 1 - The Math
Part 2.1 - What’s happening?
The reset gate controls how much of the previous hidden state to forget.
Part 2.2 - Cases
Case 1.1 If the value is close to 0
It tells the model to completely ignore or “reset” the corresponding information in the previous hidden state. This allows the model to focus on the current input without being distracted by irrelevant past information.
Case 1.2 If the value is close to 1
It allows the model to fully remember that part of the previous hidden state.
Update Gate
Part 1 - The Math
Part 2.1 - What’s happening?
The update gate controls how much of the previous hidden state to carry forward.
Case 1.1 If the value is close to 0
It tells the model to primarily update the hidden state with the new candidate information, i.e update everything in a sense.
Case 1.2 If the value is close to 1
It tells the model to carry everything forward and ignore the new candidate state.
How these gates work together?
We first compute an intermediary hidden state called the candidate hidden state or new candidate state using,
Now, we will calculate the final hidden state using the update gate,
Basically, the final state is an aggregation of how much information of the previous hidden state to preserve + how much information of the new hidden state to carry over
In the next post we will go through the coveted transformer network that powers GPT, Gemini and more.