Understanding Neural Networks: From Perceptrons to Deep Learning
Introduction: Why do we need neural networks?
Why do we need neural networks? When we start learning about machine learning we learn something called as Logistic Regression, which is a linear model that is used to predict the probability of a binary outcome. So why is that we need neural networks? Simple Answer, since it’s a linear model it cannot model complex relationships.
The Foundation: Linear Algebra, Linear Regression and Logistic Regression
Linear Algebra
Let’s focus our attention on linear algebra for a moment, I promise it will be worth it.
We will focus on matrix multiplication for now.
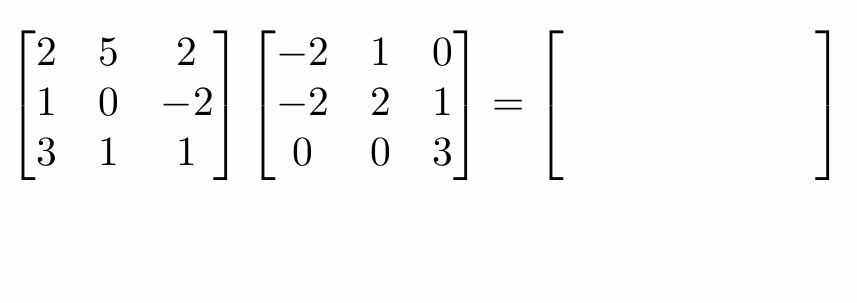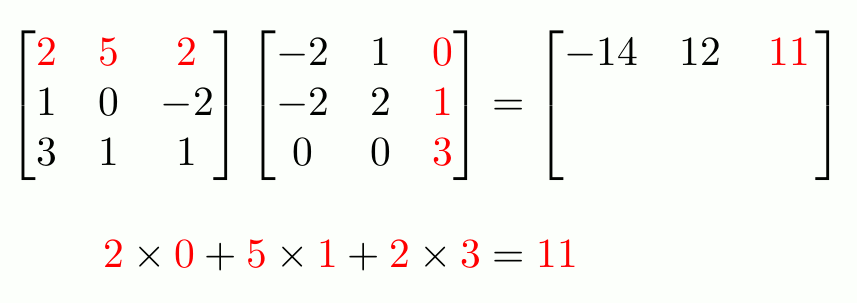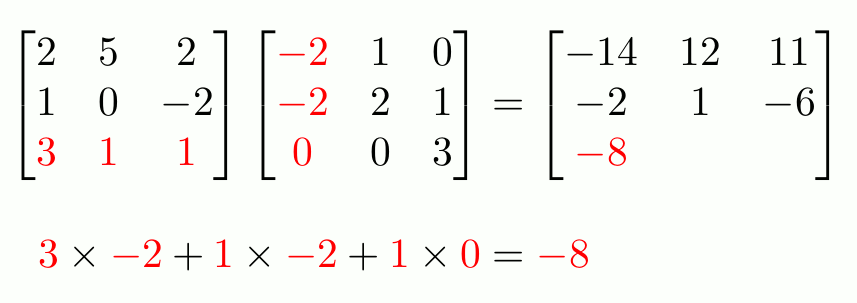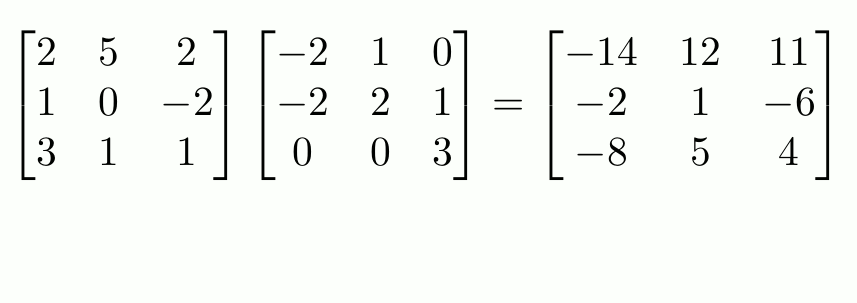
source: https://www.mscroggs.co.uk/img/full/multiply_matrices.gif
Rule: number of columns of 1st matrix = number of rows of the 2nd matrix
Once you’ve made yourself familiar with matrix multiplication, which is core to machine learning, let’s move on. What does matrix multiplication in machine learning actually signify and why do we need it in the first place?
Matrix multiplication represents linear transformations - operations that preserve lines and the origin while scaling and rotating vectors.
In machine learning, we use matrix multiplication to primarily make batch processing (processing multiple units of input simultaneously considering datasets can be in the order of billions) possible.
The other reason is so we can add non-linearity to the linear transformation using an activation function (which we will revisit in the future).
I will keep the next two topics brief,
Linear Regression
We use this algorithm to predict continuous values. It finds the best-fit line through data points by minimizing the sum of squared errors. The model learns weights (w) and bias (b) such that:
Linear regression is the foundation upon which more complex models are built, think of it as trying to fit a line through some data points which can later be used to predict the value of y given w, x and b
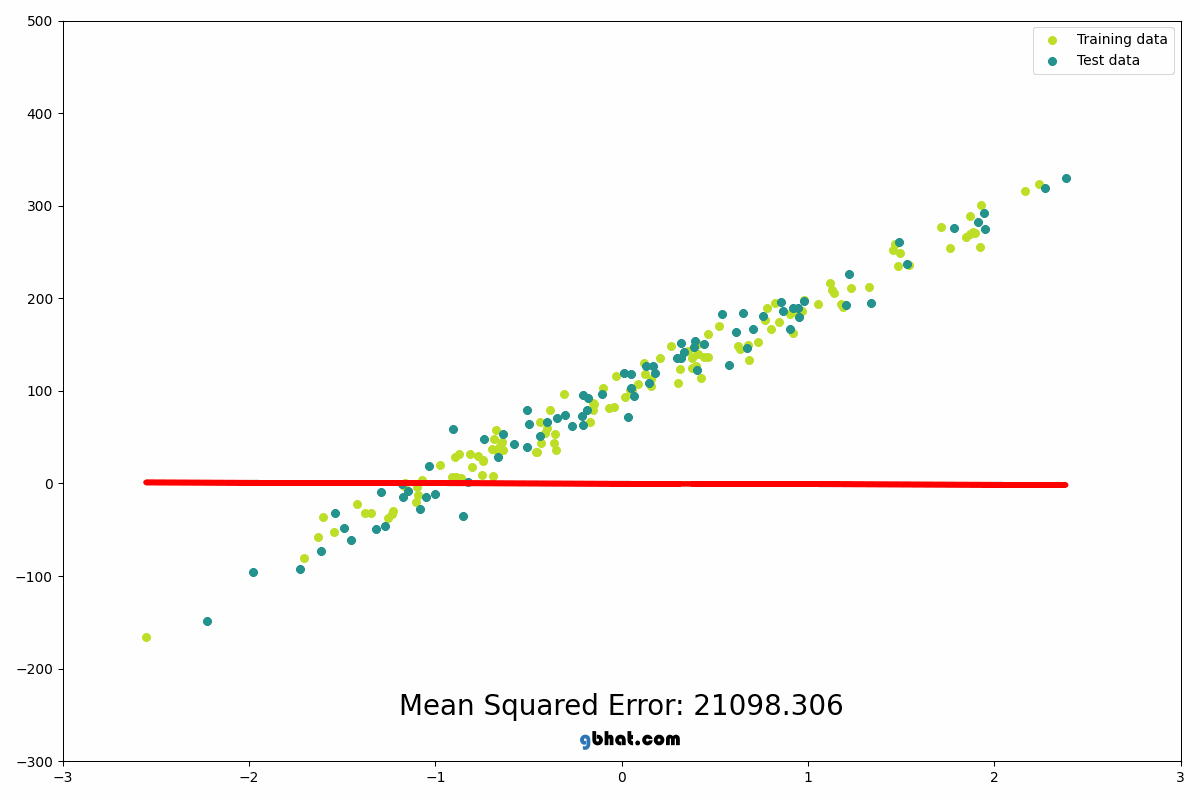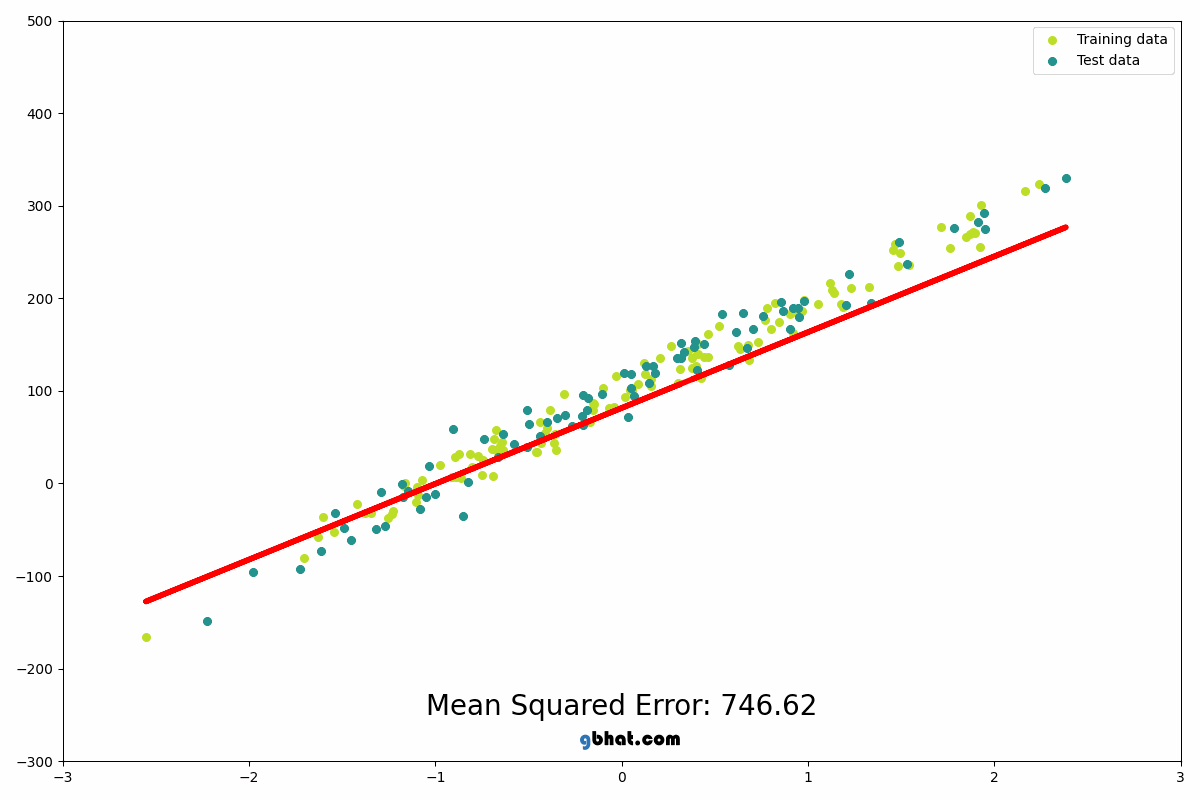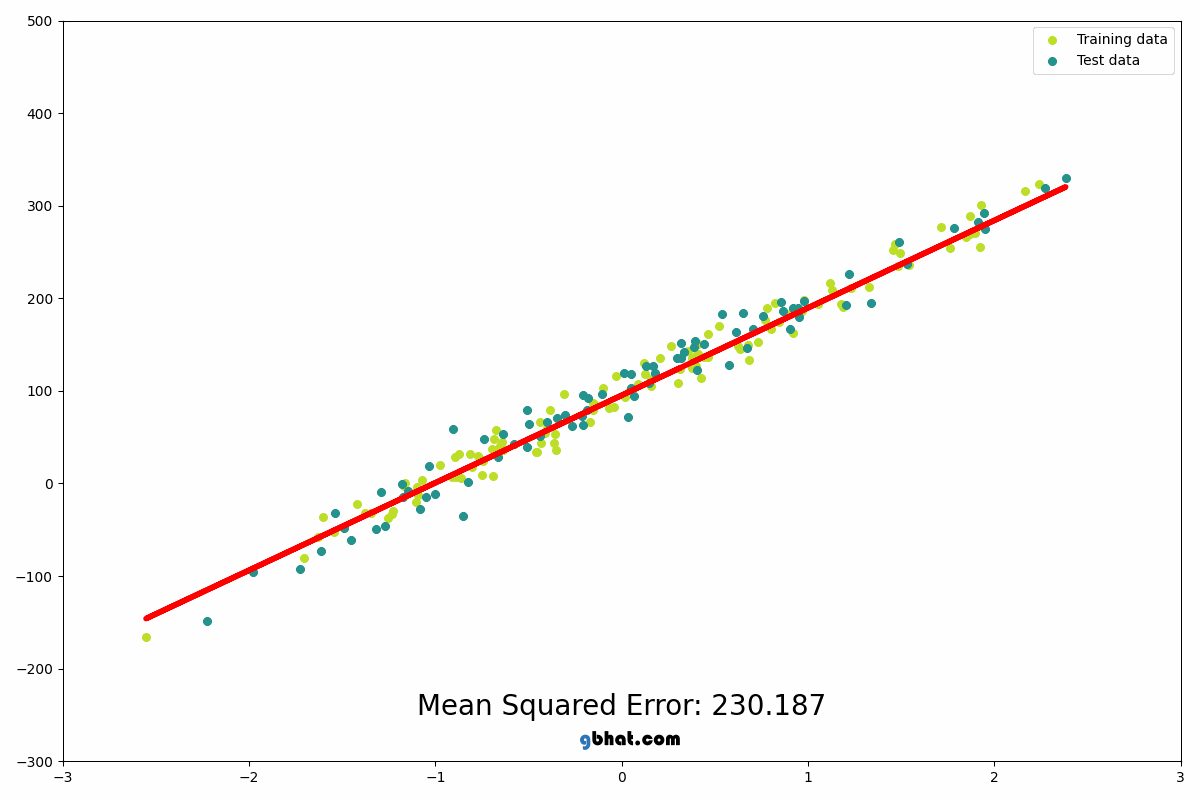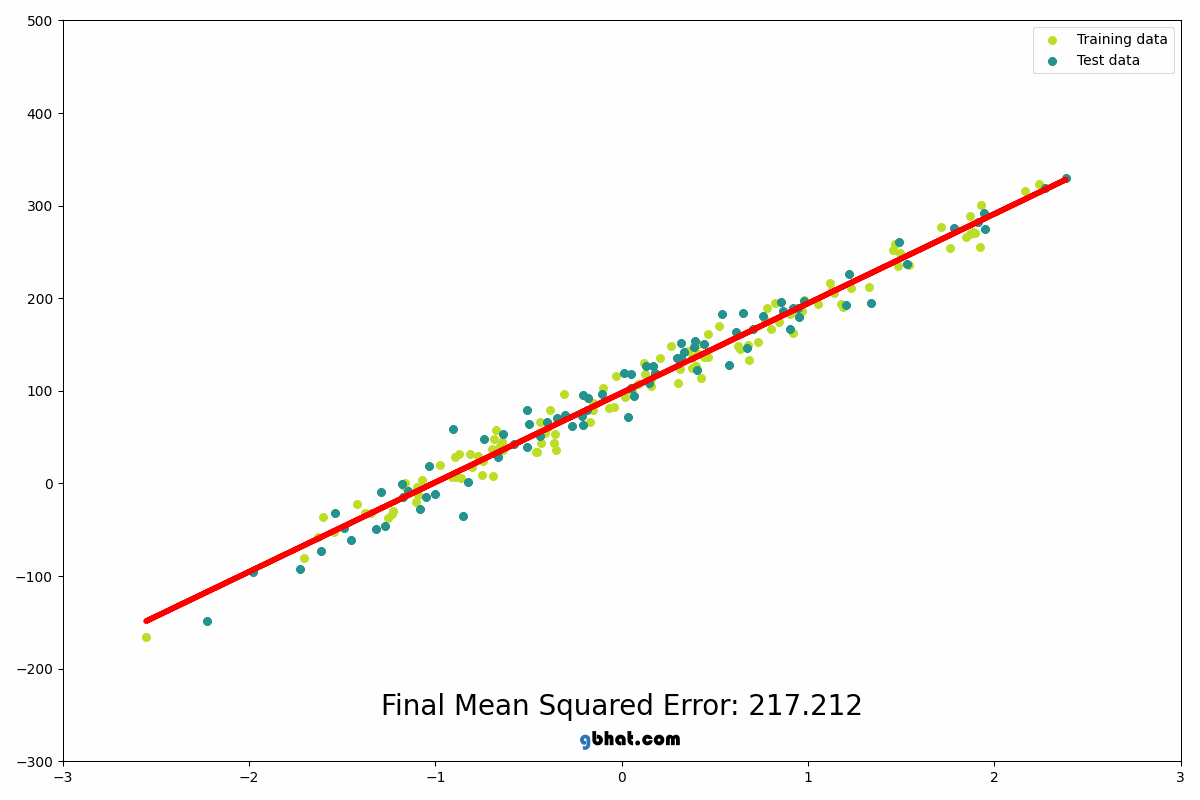 source: https://gbhat.com/assets/gifs/linear_regression.gif
source: https://gbhat.com/assets/gifs/linear_regression.gif
Logistic Regression
Logistic regression is used for binary classification problems. It applies a sigmoid function (non-linearity) to the linear output to produce probabilities between 0 and 1:
Where is the sigmoid function:
This creates an S-shaped curve that maps any real number to a probability, making it perfect for classification tasks.
 source: https://images.spiceworks.com/wp-content/uploads/2022/04/11040521/46-4-e1715636469361.png
source: https://images.spiceworks.com/wp-content/uploads/2022/04/11040521/46-4-e1715636469361.png
The difference
Simply used for different purposes - linear regression is used to predict continuous values while logistic regression is used to predict a probability.
What we have learnt so far
By now we have learnt how to multiply matrices, why we need to multiply matrices, what is linear regression and logistic regression.
Overfitting and Underfitting
Overfitting
After training, if the model performs well on the training data but doesn’t work well on the testing data, the model has overfit. This means it has memorized the training data instead of learning generalizable patterns.
Underfitting
After training, if the model performs poorly on the training data and also doesn’t work well on the testing data, the model has underfit. This means it hasn’t learned enough from the data and the learnt function is too simple for the problem.
Why This Matters
Understanding overfitting and underfitting is crucial because:
- Overfitting leads to poor generalization on new data
- Underfitting means the model is too simple to capture the underlying patterns
- Finding the right balance is key to building effective neural networks
Neural Networks
A network of nodes
Now let’s dive into the nitty-gritties of Neural Networks. Before we do that we should take a look at how data flows through the network.
 source: https://miro.medium.com/v2/resize:fit:1200/1*lGsIwcrmZ960TcvnBWSLwA.gif
source: https://miro.medium.com/v2/resize:fit:1200/1*lGsIwcrmZ960TcvnBWSLwA.gif
I know, I know what even is going on here? Don’t worry we’ll go through each step carefully
 source: https://y.yarn.co/1ab1e1b9-fd96-426d-b7d6-4d60e8294977_text.gif
source: https://y.yarn.co/1ab1e1b9-fd96-426d-b7d6-4d60e8294977_text.gif
Definitions
Now we are going to define some keywords that we are going to use in the future
- Input Layer: The first layer that receives the raw data (features)
- Hidden Layer: Intermediate layers between input and output that process the data
- Output Layer: The final layer that produces the prediction
- Neuron/Node: Individual processing units in each layer
- Weight: Parameters that determine the strength of connections between neurons, the higher the weight of some connection the more significance it carries in the network.
- Bias: Additional parameter that allows the model to shift the activation function
- Activation Function: Non-linear function applied to the weighted sum of inputs
- Forward Propagation: Process of passing data through the network from input to output
- Backward Propagation: Process of updating weights based on prediction errors
How Data Flows Through the Network
Let’s break down what happens in that animated GIF:
- Input Processing: Raw data enters the input layer
- Weighted Sum: Each neuron computes
- Activation: Apply activation function:
- Forward Pass: Results flow to the next layer
- Repeat: Process continues through all hidden layers
- Output: Final prediction emerges from the output layer
Why did we learn matrix multiplication?
Now we’ll circle back to why we learnt matrix multiplication in the first place,
Consider X to be the input vector
And W to be the weight matrix
When we compute , we’re essentially performing:
This helps parallelize the computation by computing a whole batch
The only rule you must follow is that the matrix multiplication should work
- Matrix-Vector Multiplication: gives us the weighted sum for each neuron
- Bias Addition: Adding shifts the activation function. This helps prevent overfitting
- Batch Processing: We can process multiple inputs simultaneously
This is why matrix multiplication is crucial - it allows us to:
- Efficiently compute all neuron outputs in parallel
- Scale to large datasets by processing multiple samples at once
- Vectorize operations for faster computation on GPUs
The beauty is that one matrix multiplication operation can compute the outputs for an entire layer of neurons, making neural networks computationally feasible for real-world applications.
Why Multiple Layers?
The power of neural networks comes from stacking multiple layers:
- Layer 1: Learns simple features (edges, curves)
- Layer 2: Combines simple features into complex patterns
- Layer 3+: Builds increasingly abstract representations
This hierarchical learning allows neural networks to model complex, non-linear relationships that simple linear models cannot capture.
Activation Functions
We briefly mentioned activation functions earlier. Here are the most common ones:
- Sigmoid: (0 to 1)
- ReLU: (fairly popular)
- Leaky ReLU: prevents dying ReLU problem
- Tanh: (-1 to 1)
Activation functions introduce non-linearity, which is essential for neural networks to learn complex patterns (mapping functions from input to output).
Why Different Activation Functions?
Each activation function has its advantages:
- Sigmoid: Good for probability outputs (0-1 range)
- ReLU: Most popular, computationally efficient, helps with vanishing gradients
- Leaky ReLU: Prevents the “dying ReLU” problem where neurons become inactive
- Tanh: Similar to sigmoid but centered around 0, often better for hidden layers
Training Neural Networks
The Learning Process
Training a neural network involves:
- Forward Pass: Make predictions using current weights using the following: , and for each layer we add activation to add non-linearity to the mapping function.
- Loss Function: Is primarily a function to measure the error between the predicted value in the forward pass versus the actual value. We use it to calculate the loss.
- Backward Pass: Calculate gradients and back propagate the loss by multiplying the gradient with activations and update the weights and bias accordingly.
- Update Weights: Adjust weights to reduce loss using the gradient descent algorithm.
- Repeat: Continue until the model performs well
This raises an important question: Why can’t we just find the ? The simple answer is because the loss function for a neural network is a complex non-linear function and may have multiple local minima which do not represent the most optimal solution for the loss function.
Loss Functions
Common loss functions include:
- Mean Squared Error (MSE): For regression problems
- Cross-Entropy: For classification problems
The choice of loss function depends on your specific problem type.
Gradient Descent and Backpropagation
The core optimization algorithm:
- Calculate gradients of the loss with respect to each weight,
- Update weights using:
- Learning rate controls how big steps we take. Make sure it’s neither too small (the change step is negligible) nor too large (it might overshoot the most optimal point).
 source :
source : Why do we use for every iteration and why does it work? There are 2 possible cases:
-
Negative slope - Consider a point on the left side of the function. If we find the slope at point , we find it to be negative w.r.t. the optimal point , and if we calculate the update value for using the update rule, it correctly moves positively towards the optimal point.
-
Positive slope - Consider a point on the right side of the function. If we find the slope at point , we find it to be positive w.r.t. the optimal point , and if we calculate the update value for using the update rule, it correctly moves negatively towards the optimal point.
Hence, for either case, the update rule correctly moves towards the optimal point.
Backpropagation is the algorithm that efficiently computes gradients for all weights in the network:
- Forward pass: Compute all activations and outputs
- Compute loss: Calculate the difference between prediction and target
- Backward pass: Use the chain rule to compute gradients
- Update weights: Apply gradient descent to all parameters
 source : https://miro.medium.com/1*dZNUK-2Zt80rWGM0eP0iEg.gif
source : https://miro.medium.com/1*dZNUK-2Zt80rWGM0eP0iEg.gif
What exactly is going on here? Let’s look at the math for a single layer
Consider the following neural network (ignoring the bias term for now),
 source : https://i.ytimg.com/vi/UJwK6jAStmg/hqdefault.jpg
source : https://i.ytimg.com/vi/UJwK6jAStmg/hqdefault.jpg
{kind=link}
Step 1: Consider the following matrices,
Here , defines the number of training samples
Step 2: Calculate activation for 2nd (hidden layer)
Here, represents the sigmoid activation function we defined earlier
Step 3: Calculate activation for 3rd (output layer)
Here , represents our predictions for the n samples.
Step 4: Define the cost function (for the whole dataset)
Step 5: Define the update rule for gradient descent,
Step 6.1: Let’s find ,
Using Step 3 equations we derive these partials,
Here, represents the derivative of the sigmoid activation function we defined earlier as is defined by,
The final form is given by,
Scalar multiplication of term 1 and 2 to give,
The matrix multiplication form is given by,
Step 6.2: Let’s find ,
This in essence is chain-rule used to “BACK-PROPAGATE“ the loss
Using Step 2 and 3 equations we derive these partials,
The final form is given by,
The final matrix form is given by,
-
This shows how the error δ flows backward through the activation function and gets multiplied by the input from the previous layer, which is exactly what backpropagation does - it distributes the error back through the network to update the weights.
-
Once you reach the input layer, we can use the gradient descent update rule to update the trainable parameters.
-
If you want to dive deeper into the topic, which I really suggest, read this article: https://medium.com/the-feynman-journal/what-makes-backpropagation-so-elegant-657f3afbbd
Why do we use chain-rule in backpropagation?
The chain rule is essential because neural networks are composite functions: . Where defines the layer of the neural network. To compute gradients for weights in earlier layers, we need to understand how changes affect the final loss through all subsequent layers.
By the chain rule:
This allows backpropagation to efficiently compute all gradients in one backward pass, making training of deep networks computationally feasible.
Think of it as accumulating all the loss to the first layer, which makes the algorithm much more efficient.
Conclusion
Neural networks are powerful models that can learn complex patterns by stacking multiple layers of neurons. They build upon the concepts we learned earlier:
- Matrix multiplication for efficient computation
- Linear transformations as the foundation
- Non-linear activation functions for complexity
- Proper training to avoid overfitting and underfitting
The key insight is that neural networks are essentially multiple logistic regression models stacked together, with each layer learning increasingly complex representations of the data.
Understanding overfitting and underfitting helps us build models that generalize well to new data, while the mathematical foundation of matrix operations makes these complex models computationally feasible.
In the next post, we’ll dive deeper into the paper that made ChatGPT what it is today.
References
Images and Animations Used
-
Matrix Multiplication Animation - Matrix Multiplication GIF
-
Linear Regression Visualization - Linear Regression GIF
-
Sigmoid Function Graph - Sigmoid Function Image
-
Neural Network Data Flow - Neural Network Flow GIF
-
The Office GIF - Reaction GIF
-
Neural Network for Backpropagation - https://i.ytimg.com/vi/UJwK6jAStmg/hqdefault.jpg
-
Backpropagation Visualization - Backpropagation GIF
Additional Resources
- Mathematical Notation: All mathematical formulas are rendered using KaTeX